drupal
Lanzamos Edukame.com
admin — Jue, 20/12/2012 - 13:31
Finalmente puedo anunciar que hemos lanzado la nueva web de Edúkame. Ha sido mucho esfuerzo dedicado a lanzar la mejor web que hemos realizado nunca, un desarrollo de más de seis meses.
Edúmake es una web dónde nos esforzamos a hacer la vida de los padres con hijos de 0 a 6 años más fácil con artículos de educación emocional, respondiendo consultas y vendiendo soluciones a rabietas, dormir, dejar el pañal y venta cuentos infantiles.
Edúkame es un Drupal 7 + Drupal Commerce para la tienda online. Si entráis veréis que hemos usado una navegación tipo Pinterest usando el módulo Views Fluid Grid + el módulo Views Infinite Scroll modificado para que use Jquery Inifinite Scroll.
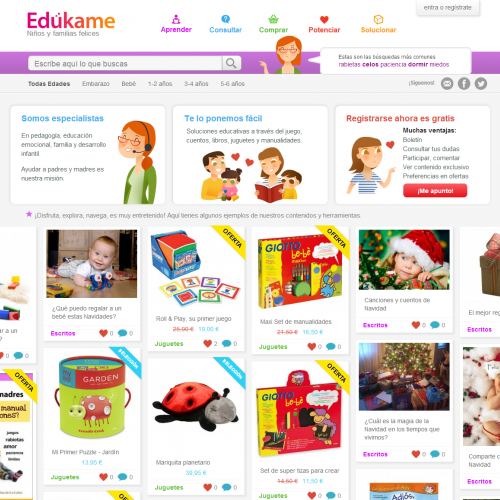
Para el tema base he usado Sasson, muy útil sobretodo por su soporte de sass y compass, algo que aún no había usado y tenía ganas.
Otra cosa a tener en cuenta es que hicimos una migración desde el antiguo blog con wordpress y desde Drupal 6 con Ubercart. Esto lo hicimos usando feeds y tuvimos bastantes problemas pero a trancas y barrancas lo conseguimos. Aunque luego hemos tenido que picar piedra a mano.
Finalmente también usamos de forma intensiva Apache Solr (usando Search API), para las búsquedas y para relacionar contenido. Aún hemos de mejorar mucho en esto pero Solr funciona por defecto bastante bien, mucho mejor que otras soluciones existentes en Drupal.
Nos queda mucho camino por recorrer pero gracias a SeedRocket y a la financiación de 100.000€ que hemos levantado tenemos un tiempo para seguir mejorando.
Ahh...si tenéis que comprar algo para un niño de 0 a 6 años os puedo dar un cupón, me lo podéis pedir a través del contacto o en los comentarios.
Vendo tienda Online de Camisetas
admin — Mié, 13/06/2012 - 17:23
Queremos vender algunos activos de Neurotic, sobretodo de los que no nos hemos podido ocupar de ellos. El primero de ellos es Tralari, una tienda online de camisetas, pero que se podría adaptar a cualquier otro tipo de producto que tenga un estilo desenfadado.

El diseño de la web es uno de sus mayores activos, personalmente me gusta mucho. A nivel técnico es un Drupal 6 con Ubercart ya preparado hasta el último detalle para vender. El domino tralari.com iría en el paquete.
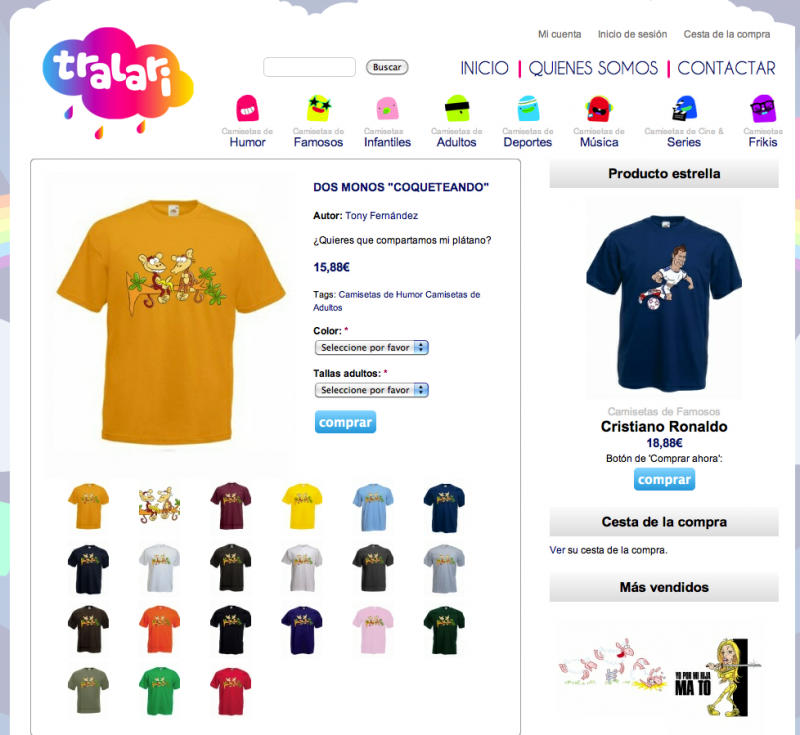
¿Hablamos? Mándame un contacto.
Migrar de wordpress a Drupal con Feeds
admin — Jue, 05/04/2012 - 22:02
Tal como comenté en el post del Proyecto Edukame la primera fase era exportar los contenidos que tenemos ahora en Wordpress a Drupal 7.
Para esto en Drupal 7 existen varias alternativas:
- Wordpress Migrate: Usando el módulo Migrate más el Wordpress Migrate puedes importar posts, usuarios, comentarios, attachments y páginas. Si lo hace todo bien es realmente bueno y recomendable ya que requiere muy poca configuración.
Desgraciadamente en mi caso todo fue mal. Muchos errores, y sobretodo comportamiento errático. A veces funcionaba casi bien, a veces muy mal. Así que después de estrellarme muchas horas con esto decidí probar otra cosa. Tal vez a ti te funcione bien y simplemente sea que no supe configurarlo.
- Módulo de 0: Otra opción es crear un módulo que lea un XML y que vaya guardando los nodos y los comentarios. No debería ser muy complicado pero para procesos largos como una importación habría que usar algo especial para que no nos de un timeout, tipo el batch API. Me lo estuve replanteando pero antes quise probar otras cosas que ya tuviesen en cuenta estas cosas. Además esta solución no permite "volver atrás", algo que siempre pasa cuando estamos configurandolo porque nunca funciona a la primera.
- Otros: Pues eso, otros, que seguro que existen y que yo desconozca o no haya tenido en cuenta
- Feeds: Lo que al final he usado y me ha ido bastante bien, aunque como todo tiene sus problemillas. A continuación explicaré como hacer una migración de wordpress a Drupal usando Feeds.
Antes de todo hemos de conseguir los datos de wordpress y como vamos a usar Feeds lo idea sería tener un XML aunque a feeds se le puede alimentar en un montón de formatos. Así que hemos de ir a wordpress y en la barra de herramientas, vamos a Exportar.
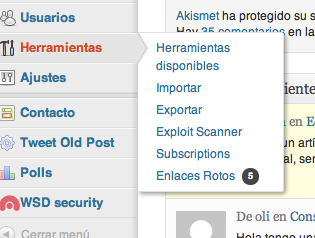
Allí le damos a exportar todo y nos devolvera un archivo WXR, que es un XML.
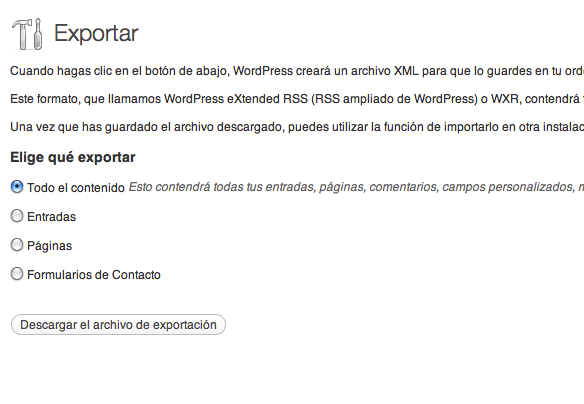
Una vez con el WXR es recomendable partirlo y tener uno de ejemplo con muy pocos posts, que lo podemos hacer simplemente editandolo.
Después de esto nos bajamos Feeds, Feeds XPath Parser, Feeds Tamper, Media Feeds y Feeds Comment Processor.
Luego los activamos tal como se ve en esta captura (y dónde también podéis ver las versiones que he usado)
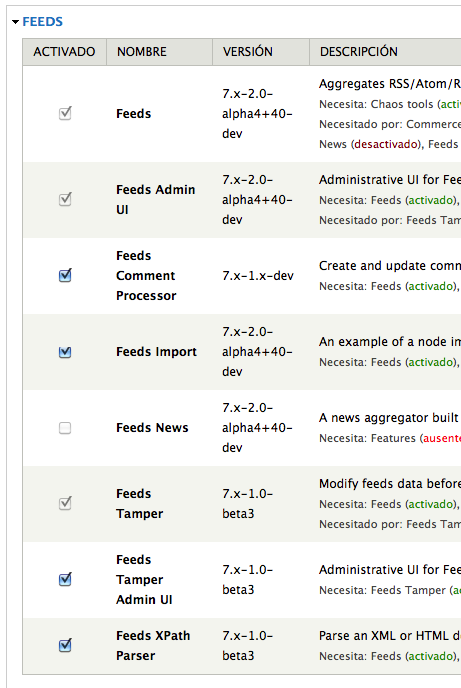
En esta captura está activado el Feeds Comment Processor pero os aconsejo desactivarlo junto a los comentarios por un error que me salió a importar los post. No guardé el error y ahora no lo encuentro. Si lo hacéis así lo único que os pasará es que luego habrá que activar los comentarios en todos los nodos importados pero ya os pongo luego como.
Una vez esto en el tipo de contenido dónde pondemos los post hemos de crear los campos de media para las imágenes (puedes ser un campo imagen, se haría todo igual), uno para los tags, otro para las categorías, otro para los nids de wordpress y otro para la url antigua de wordpress.
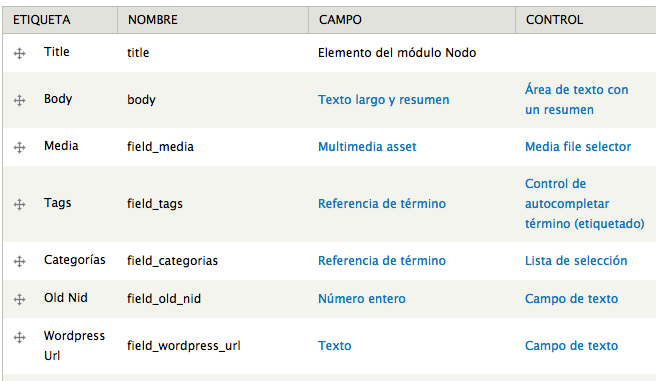
Después hemos de ir a Feeds Importers en Estructura (admin/structure/feeds/wordpress_import) y crear uno nuevo que llamaremos Wordpress Import (por ejemplo). Lo pondremos para que no haga ninguna importación periódica, que esté en un formulario sólo y que comience la importación al mandarlo. Si nuestro XML es muy grande (el mío eran sólo 750 posts) le ponemos que lo procese en background o aumentamos timeout de php. Yo por si acaso, sobretodo después de ciertos errores le aumenté todas estas variables (en la configuración de apache o en el .htaccess). Recuerda volver a la normalidad una vez hayas hecho el proceso.
php_value max_execution_time 3000
php_value max_input_time 6000
php_value upload_max_filesize 50M
php_value post_max_size 50M
php_value memory_limit 256M
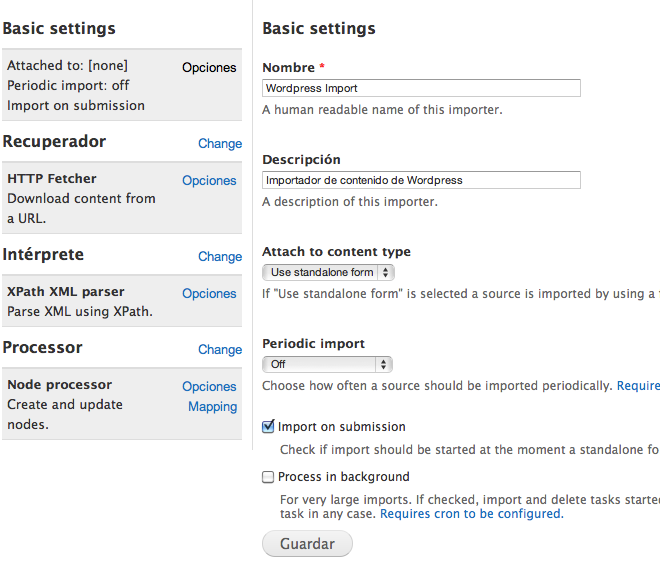
En Recuperador o Fetcher lo podemos dejar en HTTP o File Upload, da bastante igual.
En el Parser hemos de poner el XPath
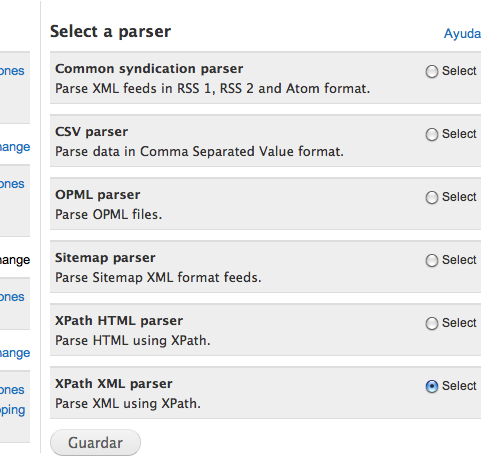
En processor hemos de poner el node processor:
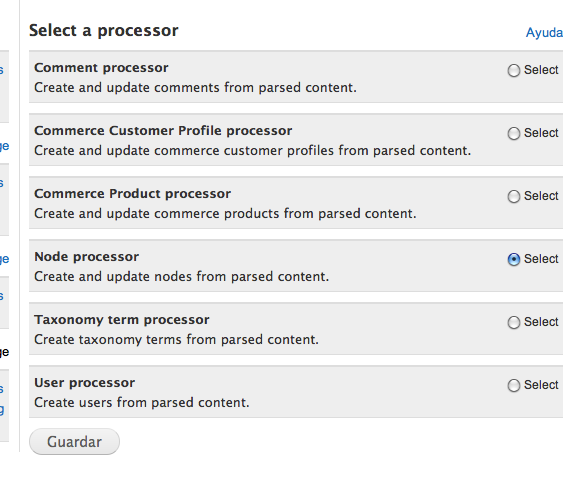
Y en las opciones del node processor hemos de poner el formato de texto en full html o configurar el filtered html para permitir los tags que nosotros queramos, pero por experiencia es mejor ponerlo en full html. Se supone que confiamos en el contenido que estamos exportando. Es recomendable instalar el módulo Wysiwyg linebreaks para que se mantengan los artículos que sin < p >'s tienen saltos de línea como separador de párrafos.
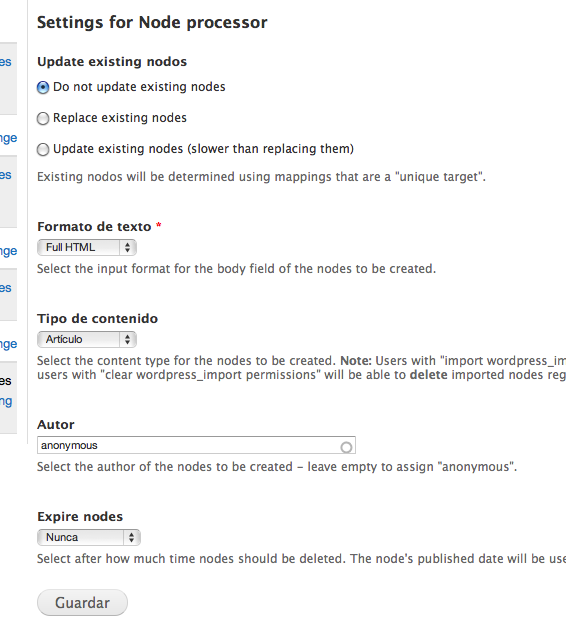
Hemos de asegurarnos que no expire y asignar los posts importados al tipo de contenido correcto, el resto de opciones no es importante si sólo estamos importando y no vamos a actualizar.
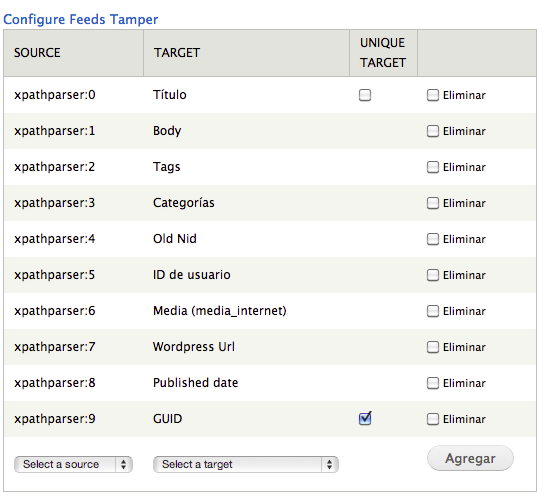
En el mapping del node processor lo que hemos de hacer ir añadiendo el origen (una expresión de XPath) de los datos al target. He añadido un unique target porque sino, y no sé muy bien porqué, me creaba nodos duplicados.
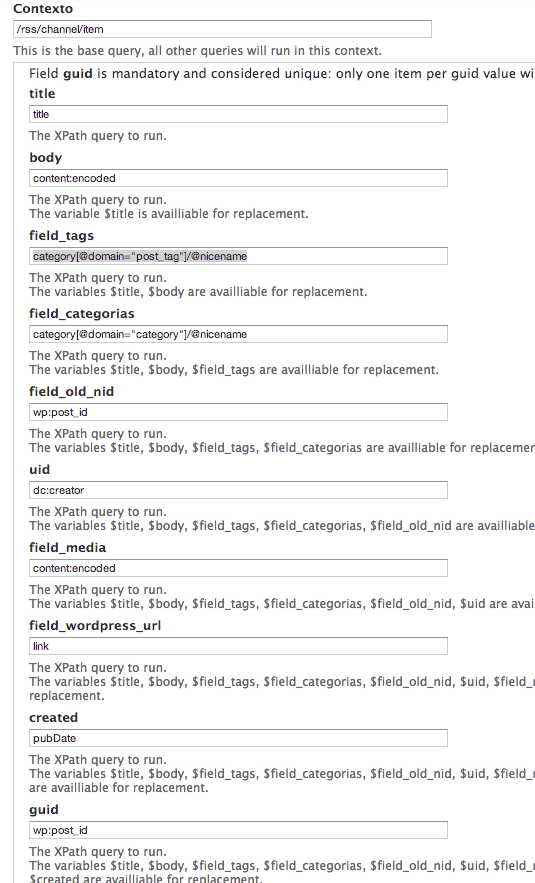
Ya casi terminando, hemos de configurar las opciones del XPath XML Parser. Para quien no sepa que es XPath se puede mirar este documento que es el que usé yo para saber cómo funciona. Es una manera fácil y potente de seleccionar los campos de un fichero XML, como si fuera un selector en CSS.
Ya sólo nos falta configurar el Feeds Tamper que tiene su intríngulis. El Feeds Tamper nos sirve para hacer transformaciones a los valores antes de guardarlos. Por ejemplo, podemos quitar espacios al principio y al final de un texto, podemos pasar a mayúsculas, reemplazar un texto por otro o simplemente quitar un string.
En nuestro caso necesitamos cambiar un nombre por un id de usuario, necesitamos extraer las imágenes del texto para pasarlas al field media y necesitamos quitarle para la url el http y el dominio. Para lo último podemos usar uno de los plugins de tamper, el "Finde Replace".
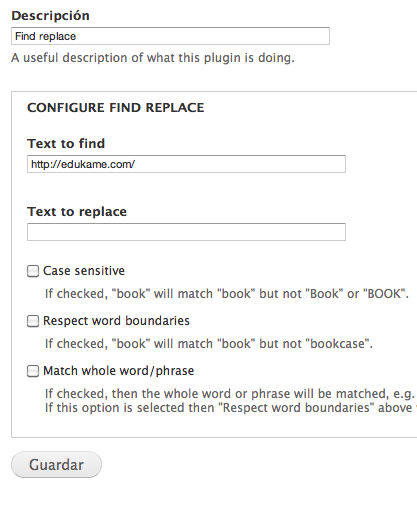
Pero para las otras dos cosas no encontré un plugin que me fuera bien. Bueno, podría haber usado una expresión regular para extraer las imágenes pero al final decidí que era más potente y flexible usar el PHP Simple HTML DOM Parser. Sobretodo por que es tolerante a html mal formados, no como una expresión regular que a no ser que sea hipersupercompleja no tiene en cuenta que esté mal escrito el tag de imagen.
Para poder añadir plugins al Feeds Tamper es relativamente fácil. Hemos de usar en un módulo el hook_ctools_plugin_directory:
/**
* Implements hook_ctools_plugin_directory().
*/
function edukame_module_ctools_plugin_directory($module, $plugin) {
if ($module == 'feeds_tamper') {
return 'plugins';
}
}
plugins es el nombre del directorio dónde ponemos los ficheros que definen cada plugin, el cual ha de estar en el mismo directorio que el módulo dónde lo hemos definido. En este caso yo lo he puesto dentro del módulo edukame_module.
Ahora, ¿como son los ficheros de los plugins? Pues aquí os pongo un par de ejemplos:
El que nos transforma los nombres de usuario de wordpress a uids (previamente hemos tenido que crear esos usuarios, con el mismo nombre de usuario que en wordpress)
wordpress_id.inc
(este lo usaremos para los comentarios)
$plugin = array(
'form' => 'feeds_tamper_wordpress_id_form',
'callback' => 'feeds_tamper_wordpress_id_callback',
'validate' => 'feeds_tamper_wordpress_id_validate',
'name' => 'Wordpress id',
'multi' => 'direct',
'category' => 'Text',
);
function feeds_tamper_wordpress_id_form($importer, $element_key, $settings) {
$form = array();
return $form;
}
function feeds_tamper_wordpress_id_validate(&$settings) {
}
function feeds_tamper_wordpress_id_callback($result, $item_key, $element_key, &$field, $settings) {
$query = new EntityFieldQuery();
$query
->entityCondition('entity_type', 'node')
->propertyOrderBy('created', 'DESC')
->fieldCondition('field_old_nid', 'value', array($field))
->range(0,1);
$result = $query->execute();
$nids = array_keys($result['node']);
$field = array_pop($nids);
}
user_import.inc
$plugin = array(
'form' => 'feeds_tamper_user_import_form',
'callback' => 'feeds_tamper_user_import_callback',
'validate' => 'feeds_tamper_user_import_validate',
'name' => 'User Import',
'multi' => 'direct',
'category' => 'Text',
);
function feeds_tamper_user_import_form($importer, $element_key, $settings) {
$form = array();
return $form;
}
function feeds_tamper_user_import_validate(&$settings) {
}
function feeds_tamper_user_import_callback($result, $item_key, $element_key, &$field, $settings) {
$owner = user_load_by_name($field);
$field = $owner->uid;
}
image_extractor.inc
$plugin = array(
'form' => 'feeds_tamper_image_extractor_form',
'callback' => 'feeds_tamper_image_extractor_callback',
'validate' => 'feeds_tamper_image_extractor_validate',
'name' => 'Image extractor',
'multi' => 'direct',
'category' => 'Text',
);
function feeds_tamper_image_extractor_form($importer, $element_key, $settings) {
$form = array();
return $form;
}
function feeds_tamper_image_extractor_validate(&$settings) {
}
function feeds_tamper_image_extractor_callback($result, $item_key, $element_key, &$field, $settings) {
include_once(DRUPAL_ROOT . base_path() . drupal_get_path('module','edukame_module') . '/simplehtmldom_1_5/simple_html_dom.php');
$images = array();
$post_dom = str_get_html($field);
if($post_dom && is_object($post_dom) && isset($post_dom->nodes)){
$img_tags = $post_dom->find('img');
foreach($img_tags as $image) {
if (module_exists('transliteration')) {
$image->src = transliteration_get($image->src);
}
$images[] = $image->src;
}
}
$field = $images;
}
Para este último has de tener en cuenta que yo puse el simplehtmldom dentro de la carpeta del módulo edukame, en la misma carpeta que están los plugins.
Entonces si vamos a las opciones de Tamper han de salir activados los plugins tal que así:
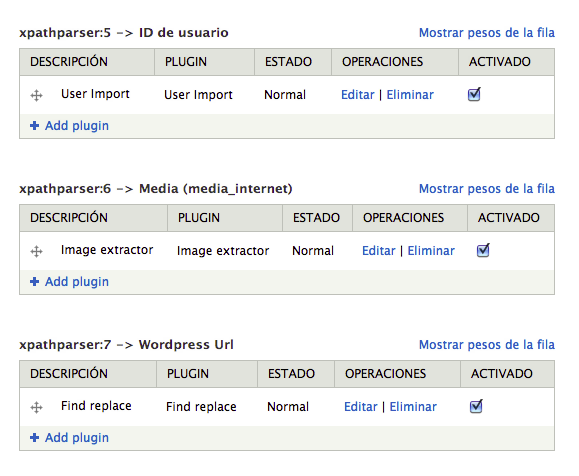
La url la hemos guardado para tener las mismas url's que en wordpress, así que nos falta configurar el pathauto para que pille el campo url. Nos vamos a configuración, alias de url y finalmente patters y ponemos:
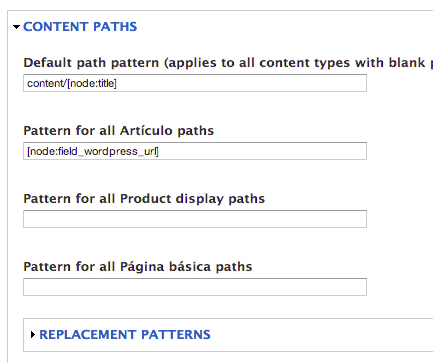
Sólo os tenéis que fijar en la url del tipo de contenido artículo o el que hayáis escogido vosotros.
Antes de finalizar es totalmente recomendable hacer un backup de la base de datos ya que aunque Feeds nos permite volver atrás y borrar los nodos esto no siempre funciona si la importación fue realmente mal.
Para hacer un backup puedes usar el módulo Backup and Migrate o una sencilla sentencia de drush:
drush sql-dump > exportacion-configurado-feeds.sql
Ahora sólo nos falta ir a /import, escoger el wordpress import, poner la url del xml (o subirlo, dependiendo de cómo lo hayamos configurado) y esperar. Lo siento, seguramente habrá ido mal.
Posibles errores que te pueden pasar y que a mi me pasaron:
This page contains the following errors:
error on line 49832 at column 16: Opening and ending tag mismatch: encoded line 0 and script
Below is a rendering of the page up to the first error.
Esto me pasó porque el xml estaba mal formado, en mi caso era porque en algunas páginas teníamos código javascript y wordpress al exportar no lo mete bien dentro de un CDATA, o se lo pone dos veces, no recuerdo exactamente. Pero lo importante para resolver este problema es ver el archivo con Firefox porque te indicará la línea dónde está el problema. Vas a esa línea y lo editas para solucionarlo.
Mayúsculas: Este es un error realmente curioso, si tienes dos ficheros (imágenes por ejemplo) que se llaman igual pero se diferencian en las mayúsculas, imagen.jpg Imagen.jpg, entonces te dirá que está duplicado.
Es un bug del core: http://drupal.org/node/966210
¿Qué solución tiene esto? Pues o esperar a que lo arreglen o si no son muchos cambiarlos a mano, que es lo que hice yo.
Caracteres UTF en las url's (ñ's, acentos): Otro de esos bugs tan guays del core aunque yo lo puse en media_internet http://drupal.org/node/1492658
Si subes una imagen con ñ's o acentos, por ejemplo, el módulo transliterate lo hace genial pero en cambio si la añades desde una url no lo hace bien.
Mi solución para esto fue hacer una copia en el mismo directorio de los archivos culpables quitándoles los caracteres "raros". Así no tuve que modificar los posts en wordpress y sólo tuve que hacer un transliteration en el plugin dónde extraía las imágenes.
Esto no sé muy bien porqué era, pero me pasaba al poner el xml entero. Lo que hice para minimizar el problema fue exportar el archivo por autores y así tener ficheros más pequeños y problemas más localizados. Esto puede que no sea una opción para ti, entonces mira a ver si alguien ha contestado este bug: http://drupal.org/node/1508154
Los comentarios
Ahora sólo nos falta importar los comentarios, lo cual después de todo lo otro es casi pan comido. Activamos los módulos comments y Feeds Comment Processor. Creamos un nuevo feed importer, le asignamos como processor el comment processor:
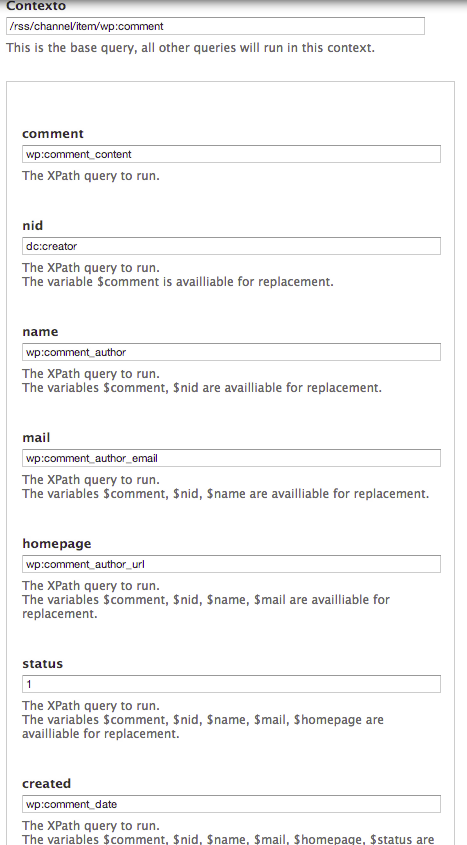
Configuramos el mapping:
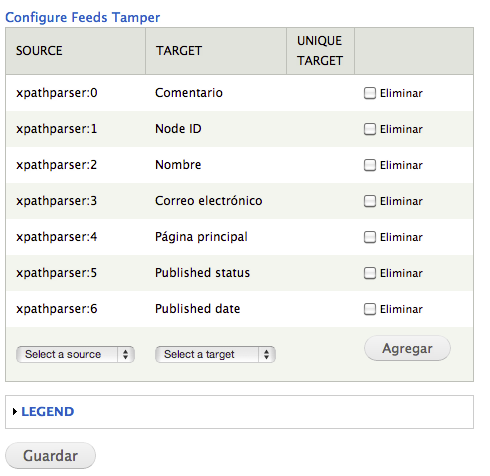
Y configuramos el XPath
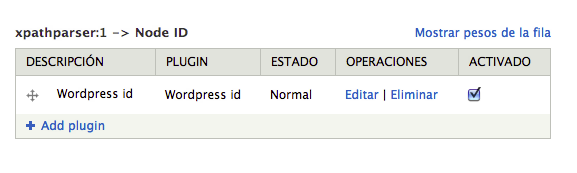
Finalmente sólo queda activar el plugin de tamper wordpress id para convertir los id's de wordpress en id's de drupal:
Ahora volvemos a crear un backup de la base de datos, vamos al formulario de importación, ponemos otra vez el XML entero y esperamos...uppss, volvió a ir mal?
Errores que me encontré yo:
Cuando el módulo feeds_comment_processor añade los comentarios lo hace en el orden en el que aparecen. La exportación de wordpress sí exporta el comment_ID pero esto Drupal no lo usa y wordpress los exporta en el orden que le da la gana. Para solucionar esto es más fácil modificar wordpress, es tan sólo una línea.
También te puede pasar que te un error de sql y te diga que el nombre es demasiado largo (creo que son 256) con lo cual te puedes preguntar. ¿Quien ha puesto un nombre así de largo? Y la respuesta es que son los pingbacks así que lo que yo hice fue quitarlos porque tampoco me interesaban.
Para eliminar pingbacks y ordenar los comentarios has de ir a la línea 403 del archivo wp-admin/includes/export.php y dejarlo así:
<?php $comments = $wpdb->get_results( $wpdb->prepare( "SELECT * FROM $wpdb->comments WHERE comment_post_ID = %d AND comment_approved <> 'spam' AND comment_type <> 'pingback' ORDER BY comment_ID ASC", $post->ID ) );
Finalmente si teníamos desactivados los comentarios al importar los posts nos encontraremos que no tendremos activados los comentarios en todos nuestros nodos importados. Para no tenerlos que hacer manualmente podemos hacer:
UPDATE node SET comment = 1 WHERE type = 'article'
UPDATE node_revision LEFT JOIN node ON node.nid = node_revision.nid SET node_revision.comment = 2 WHERE node.type = 'article'
Esto se puede hacer desde drush asi:
drush sqlq "UPDATE node SET comment = 1 WHERE type = 'article'"
drush sqlq "UPDATE node_revision LEFT JOIN node ON node.nid = node_revision.nid SET node_revision.comment = 2 WHERE node.type = 'article'"
Y ufff...creo que esto es todo. Seguramente con un post tan largo me habré olvidado de cosas, otras estarán mal y seguramente os saldrán problemas nuevos que a mi no me pasaron. De todas maneras espero que sea una guía muy útil para que al menos os tengáis que pelear menos de lo que lo tuve que hacer yo.
El próximo paso será importar los productos de una tienda con Drupal 6 + Ubercart a Drupal 7 con Drupal Commerce.
Proyecto edukame
admin — Mié, 15/02/2012 - 12:25
Desde hace un tiempo estoy en el equipo de edukame.com pero dedicando pocas horas de Neurotic. Ahora nos vamos a poner a fulltime para conseguir que edukame sea la referencia en el sector de educación infantil y en la venta de libros y juguetes para niños.
Para conseguir esto vamos a tener que rehacer la web. En este post pondré los pasos que creo que tendré que hacer y a medida que los vaya haciendo iré creando posts explicando más o menos en detalle lo que he hecho:
- Migración de Wordpress a Drupal: Edukame está en wordpress la parte de contenidos y en Drupal 6 + Ubercart la tienda y la nueva será un Drupal 7 + Drupal Commerce.
- Maquetación: Tendré que aplicar el nuevo diseño (aún en fase inicial) y escoger qué tema base usar. Imprescindible que el tema base sea responsive. Después habrá que maquetar versiones móvil, tablet y desktop.
- Búsqueda: Esto será una parte fundamental de la web por lo que usaré Apache Solr para conseguir que los resultados sean realmente relevantes y rápidos.
- Aplicaciones para móviles y web: Juegos, utilidades para madres y padres, etc. Muy importante.
- Integración con redes sociales: Facebook, twitter, google+, etc.
- Analíticas: Integración de analitics con eventos, túneles, etc. Incorporación de otras herramientas tipo crazyegg para ver el comportamiento de los usuarios. No se puede mejorar sin medir.
- Test A/B y multivariantes: Lo mismo de antes, no se puede mejorar sin medir.
- Newsletters: Aunque a muchos desarrolladores nos parezca como algo anticuado el mail es el mejor canal que existe para llegar a tus usuarios.
- Test de usabilidad: No sabes cuales pueden ser los obstáculos reales hasta que no lo pruebas con tu público. Uno mismo no es para nada el público objetivo normalmente. Así que más mediciones todavía!
Viaje a la Tierra Media
Carlos — Jue, 17/11/2011 - 13:37
¿Eres un apasionado del mundo de J.R.Tolkien y siempre has querido viajar a la Tierra Media, conocer a hobbits, luchar contra los orcos junto a elfos y enanos?
Pues ahora puedes realizar el viaje a la Tierra Media de tus sueños gracias a la última promoción de Viajes Monllar.
Nosotros ya lo hicimos y aquí tenéis las pruebas fotográficas:



También podéis hacer un viaje al Centro de la Tierra y Viaje alucinante.
Como supongo que ya suponéis, no son viajes reales, sino nuestro último intento de marketing viral. ¿Qué te parece? ¿Es lo suficientemente gracioso o curioso como para que se lo pasaras a un amigo, lo pusieras en tu muro del facebook o en twitter?

Comentarios recientes
hace 3 años 6 semanas
hace 3 años 39 semanas
hace 3 años 47 semanas
hace 4 años 3 días
hace 4 años 8 semanas
hace 4 años 8 semanas
hace 4 años 9 semanas
hace 4 años 10 semanas
hace 4 años 10 semanas
hace 4 años 11 semanas